NIH funded GPU Computing Cluster - Panther
Please acknowledge NIH S10OD034382 in publications using the MGCF.
If you use the MGCF in your research, please acknowledge that your calculations were done in the MGCF using NIH S10OD034382 funded equipment. Send mgcf@berkeley.edu the reference for any resulting publications. This makes a HUGE difference with regard to our ability to get future funding.
See the funding details. The new cluster is named Panther.
Panther Cluster: has > 1.8 Petabyte of data storage for user projects and 1.3PB of additional backup disk storage.
This is made up of 480 TB of ultra fast SSD plus 1.32PB on a fast dedicated disk array.
There is an additional 1.32PB data storage on a fully redundant fast dedicated disk array for data backups.
Panther's main GPU nodes:
NVIDIA Quadro RTX A6000 GPU unit (2 nodes, 2 GPUs per node, 64 CPU core per node, 16 total GPUs in 8 nodes; 512GB RAM per node)
NVIDIA Quadro RTX A6000 GPU unit (2 nodes, 1 GPU per node, 64 CPU core per node, 8 total GPUs in 8 nodes; 512GB RAM/node)
Per RTX A6000 GPU specs:
GPU memory 48 GB GDDR
CUDA Cores 10752
NVIDIA Tensor Cores 336
NVIDIA RT Cores 84
Single-precision performance 38.7 TFLOPS
RT Core performance 75.6 TFLOPS
Tensor performance 309.7 TFLOPS
There are 4 additional interactive GPU nodes on order. These nodes are for people to work out the bugs in their processes before
submission to the main cluster GPU nodes.
These nodes are Intel Xeon 38 CPU core, 128GB RAM, 1 NVIDIA GeForce RTX 4080 16G GDDR6x GPU, 1TB SSD scratch space.
Per RTX 4080 GPU specs:
NVIDIA CUDA Cores 9728
Memory Size 16 GB
Ray Tracing Cores - 3rd Generation
Tensor Cores - 4th Generation
NVIDIA Architecture - Ada Lovelace
Panther Totals: 16 GPU nodes with a total of 24 RTX A6000 GPUs (total: 258048 CUDA core, 8064 Tensor core, 2016 RT core), 8192GB total RAM, 1024 total CPU core and 1.8PB disk space and 1.3PB backup disk space, all on high speed disk arrays or SSD.
+ 4 GPU interactive nodes: with a totals of 4 NVIDIA GeForce RTX 4080 16G GDDR6x GPUs (16320 total CUDA core), 152 CPU core, 512GB RAM, 4TB SSD scratch space.
CPU nodes (originally on Tiger cluster): Also funded by NIH, the CPU cluster has of 36 CPU nodes each with 64 core and 512GB RAM per node.
CPU Totals: 36 CPU nodes for a total of 2304 CPU core, and 18432GB total RAM, 100TB disk array + 100TB backup disk device all on high speed disk arrays with SSD buffering. There is also a older GPU node with 8 Nvida Tesla cards (= 30400 GPU core).
Tiger's nodes were merged with Panther for a single unified cluster running Rocky Linux with
Warewulf clustering and
Slurm scheduling.
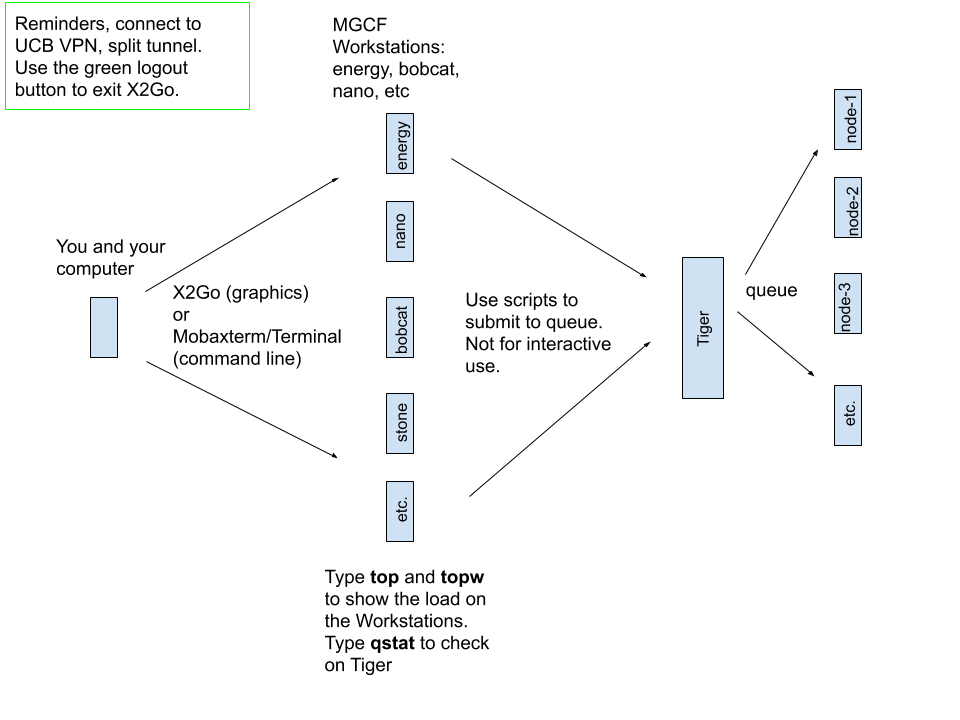
We have cpu/gpu workstations that act as login interfaces to Panther. They have the same software suite as Panther but are not managed via Slurm.
MGCF Workstations
In 175 Tan Hall, there are twelve powerful workstations running Linux. Each has 12-32 core, high quality NVIDIA graphics and plenty of local disk space. See CPU, RAM and GPU details. All of the workstations have 32 inch 4K resolution screens.For day to day work, all of the workstations are interchangeable and it is recommended that you use one of these for remote access, rather than the Panther computing cluster. Your files are network mounted across all and the workstations have a wider range of interactive software than the server. There will be better load balancing and stability on the server if you use a workstation for interactive use, either in person or remotely.
The MGCF workstations are named machinename.cchem.berkeley.edu where machinename is one of these names:
wilma, ocelot, civet, energy, nano, bobcat, lynx, barney, lava, slate, stone, betty, bronto (running Rocky Linux 9) and gravel, bambam which run Centos Linux 7. [May be retired/replaced in 2025]
.
A full suite of development, graphics, chemistry and other scientific tools is available. Please see the the software page for details.
You can see the load on these workstations with the topw command. It will
show the top processes on each machine.
NSF funding
We are still using some parts of our NSF funded computing cluster from: NSF CHE-0840505.
These NSF nodes are currently part of the MGCF workstation grouping.